Real Time Face Mask Detection System

This project is divided into two parts: Face identification and Mask recognition. We have gone through steps of Mask recognition in previous project, hence we dive into building a face identification system and usage of Mask recognition system.
The project flow is shown in the block diagram below:
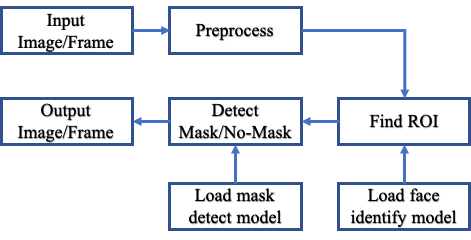
In order to build a face identification system we use use the existing caffe-based face identification model. We load our model using OpenCV’s deep neural network module with Caffe models cv2.dnn.readNet and specify two sets of files: (1) .prototxt file(s) which defines the model architectures i.e., its layers and other parameters and (2) .cafeemodel file which contains the weight for those layers. We used the model present in face detector subdirectory of dnn samples. We also load the model trained from FaceMaskDetector project. Once we are done with loading models. Let’s dive into the process.
net = cv2.dnn.readNet("deploy.prototext", "res10_300x300_ssd_iter_140000.caffemodel")
model = load_model(model_save_path);
The following process holds same for video and image as every frame in a video is image, hence we understand the process of what happens after image is loaded. Once the image is loaded we construct a blob from the image using cv2.dnn.blobFromImage using OpenCV and then provide the blobs as input to the network (Face identification model) and perform a forward pass to find detections. To understand more in details relating to cv2.dnn.blobFromImage please read this page.
blob = cv2.dnnblobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))
net.setInput(blob)
detections = net.forward()
Once we have one or more detections, for every detections (face) we run the facemask detection model to find if the face is covered with mask or not. startX, startY, endX and endY are start and end points of the face detections. Basically we send the face part to the processing stage and convert from BGR to RGB as OpenCV performs BGR operation. Then we resize to the shape we used in our model network i.e., 224 by 224 and preprocess using preprocess_input provided by tensorflow.keras.applications.mobilenet_v2. After the face is preprocessed we classify it as mask and without mask by running model.predict.
face = image[startY:endY, startX:endX]
face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB)
face = cv2.resize(face, (224, 224))
face = img_to_array(face)
face = preprocess_input(face)
face = np.expand_dims(face, axis=0) # from (224, 224, 3) to (1, 224, 224, 3)
(mask, withoutMask) = model.predict(face)[0]
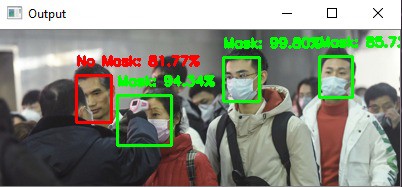
Example Results
The static images were collected from
kaggle. Some of the result for images are shown below.


A real time video implementation is shown below:
Credits
Sunny Arokia Swamy Bellary
Research Engineer - Robotics
EPRI Engineer | AI Enthusiast | Computer Vision Researcher | Robotics Tech Savvy | Food Lover | Wanderlust | Team Leader @Belaku | Musician |