Reducing Traffic Mortality in the USA
Introduction
1. The raw data files and their format

While the rate of fatal road accidents has been decreasing steadily since the 80s, the past ten years have seen a stagnation in this reduction. Coupled with the increase in number of miles driven in the nation, the total number of traffic related-fatalities has now reached a ten year high and is rapidly increasing.
Per request of the US Department of Transportation, we are currently investigating how to derive a strategy to reduce the incidence of road accidents across the nation. By looking at the demographics of traffic accident victims for each US state, we find that there is a lot of variation between states. Now we want to understand if there are patterns in this variation in order to derive suggestions for a policy action plan. In particular, instead of implementing a costly nation-wide plan we want to focus on groups of states with similar profiles. How can we find such groups in a statistically sound way and communicate the result effectively?
To accomplish these tasks, we will make use of data wrangling, plotting, dimensionality reduction, and unsupervised clustering.
The data given to us was originally collected by the National Highway Traffic Safety Administration and the National Association of Insurance Commissioners. This particular dataset was compiled and released as a CSV-file by FiveThirtyEight under the CC-BY4.0 license.
# Check the name of the current folder
current_dir = !pwd
print(current_dir)
# List all files in this folder
file_list = !ls
print(file_list)
# List all files in the datasets directory
dataset_list = !ls datasets/
print(dataset_list)
# View the first 20 lines of datasets/road-accidents.csv
accidents_head = !head -n20 datasets/road-accidents.csv
accidents_head
['/home/repl']
['datasets']
['miles-driven.csv', 'road-accidents.csv']
['##### LICENSE #####',
'# This data set is modified from the original at fivethirtyeight (https://github.com/fivethirtyeight/data/tree/master/bad-drivers)',
'# and it is released under CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/)',
'##### COLUMN ABBREVIATIONS #####',
'# drvr_fatl_col_bmiles = Number of drivers involved in fatal collisions per billion miles (2011)',
'# perc_fatl_speed = Percentage Of Drivers Involved In Fatal Collisions Who Were Speeding (2009)',
'# perc_fatl_alcohol = Percentage Of Drivers Involved In Fatal Collisions Who Were Alcohol-Impaired (2011)',
'# perc_fatl_1st_time = Percentage Of Drivers Involved In Fatal Collisions Who Had Not Been Involved In Any Previous Accidents (2011)',
'##### DATA BEGIN #####',
'state|drvr_fatl_col_bmiles|perc_fatl_speed|perc_fatl_alcohol|perc_fatl_1st_time',
'Alabama|18.8|39|30|80',
'Alaska|18.1|41|25|94',
'Arizona|18.6|35|28|96',
'Arkansas|22.4|18|26|95',
'California|12|35|28|89',
'Colorado|13.6|37|28|95',
'Connecticut|10.8|46|36|82',
'Delaware|16.2|38|30|99',
'District of Columbia|5.9|34|27|100',
'Florida|17.9|21|29|94']
2. Read in and get an overview of the data
Next, we will orient ourselves to get to know the data with which we are dealing.
# Import the `pandas` module as "pd"
# ... YOUR CODE FOR TASK 2 ...
import pandas as pd
# Read in `road-accidents.csv`
car_acc = pd.read_csv("datasets/road-accidents.csv", comment='#', sep='|')
# Save the number of rows columns as a tuple
rows_and_cols = car_acc.shape
print('There are {} rows and {} columns.\n'.format(
rows_and_cols[0], rows_and_cols[1]))
# Generate an overview of the DataFrame
car_acc_information = car_acc.info()
print(car_acc_information)
# Display the last five rows of the DataFrame
car_acc.tail()
There are 51 rows and 5 columns.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 51 entries, 0 to 50
Data columns (total 5 columns):
state 51 non-null object
drvr_fatl_col_bmiles 51 non-null float64
perc_fatl_speed 51 non-null int64
perc_fatl_alcohol 51 non-null int64
perc_fatl_1st_time 51 non-null int64
dtypes: float64(1), int64(3), object(1)
memory usage: 2.1+ KB
None
| state | drvr_fatl_col_bmiles | perc_fatl_speed | perc_fatl_alcohol | perc_fatl_1st_time | |
|---|---|---|---|---|---|
| 46 | Virginia | 12.7 | 19 | 27 | 88 |
| 47 | Washington | 10.6 | 42 | 33 | 86 |
| 48 | West Virginia | 23.8 | 34 | 28 | 87 |
| 49 | Wisconsin | 13.8 | 36 | 33 | 84 |
| 50 | Wyoming | 17.4 | 42 | 32 | 90 |
3. Create a textual and a graphical summary of the data
We now have an idea of what the dataset looks like. To further familiarize ourselves with this data, we will calculate summary statistics and produce a graphical overview of the data. The graphical overview is good to get a sense for the distribution of variables within the data and could consist of one histogram per column. It is often a good idea to also explore the pairwise relationship between all columns in the data set by using a using pairwise scatter plots (sometimes referred to as a "scatterplot matrix").
# import seaborn and make plots appear inline
import seaborn as sns
%matplotlib inline
# Compute the summary statistics of all columns in the `car_acc` DataFrame
sum_stat_car = car_acc.describe()
print(sum_stat_car)
# Create a pairwise scatter plot to explore the data
# ... YOUR CODE FOR TASK 3 ...
sns.pairplot(sum_stat_car)
drvr_fatl_col_bmiles perc_fatl_speed perc_fatl_alcohol \
count 51.000000 51.000000 51.000000
mean 15.790196 31.725490 30.686275
std 4.122002 9.633438 5.132213
min 5.900000 13.000000 16.000000
25% 12.750000 23.000000 28.000000
50% 15.600000 34.000000 30.000000
75% 18.500000 38.000000 33.000000
max 23.900000 54.000000 44.000000
perc_fatl_1st_time
count 51.00000
mean 88.72549
std 6.96011
min 76.00000
25% 83.50000
50% 88.00000
75% 95.00000
max 100.00000
<seaborn.axisgrid.PairGrid at 0x7fda61a1cb00>
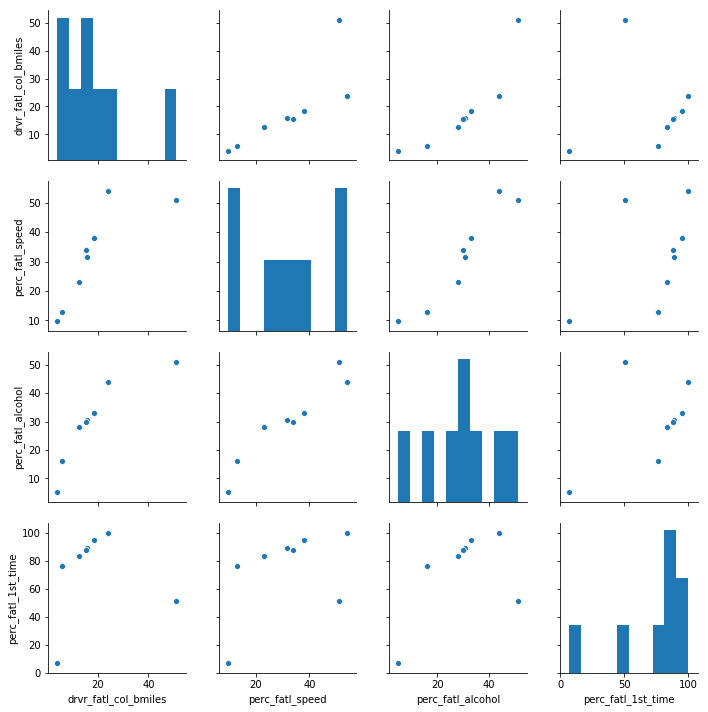
4. Quantify the association of features and accidents
We can already see some potentially interesting relationships between the target variable (the number of fatal accidents) and the feature variables (the remaining three columns).
To quantify the pairwise relationships that we observed in the scatter plots, we can compute the Pearson correlation coefficient matrix. The Pearson correlation coefficient is one of the most common methods to quantify correlation between variables, and by convention, the following thresholds are usually used:
- 0.2 = weak
- 0.5 = medium
- 0.8 = strong
- 0.9 = very strong
# Compute the correlation coefficent for all column pairs
corr_columns = car_acc.corr()
corr_columns
| drvr_fatl_col_bmiles | perc_fatl_speed | perc_fatl_alcohol | perc_fatl_1st_time | |
|---|---|---|---|---|
| drvr_fatl_col_bmiles | 1.000000 | -0.029080 | 0.199426 | -0.017942 |
| perc_fatl_speed | -0.029080 | 1.000000 | 0.286244 | 0.014066 |
| perc_fatl_alcohol | 0.199426 | 0.286244 | 1.000000 | -0.245455 |
| perc_fatl_1st_time | -0.017942 | 0.014066 | -0.245455 | 1.000000 |
5. Fit a multivariate linear regression
From the correlation table, we see that the amount of fatal accidents is most strongly correlated with alcohol consumption (first row). But in addition, we also see that some of the features are correlated with each other, for instance, speeding and alcohol consumption are positively correlated. We, therefore, want to compute the association of the target with each feature while adjusting for the effect of the remaining features. This can be done using multivariate linear regression.
Both the multivariate regression and the correlation measure how strongly the features are associated with the outcome (fatal accidents). When comparing the regression coefficients with the correlation coefficients, we will see that they are slightly different. The reason for this is that the multiple regression computes the association of a feature with an outcome, given the association with all other features, which is not accounted for when calculating the correlation coefficients.
A particularly interesting case is when the correlation coefficient and the regression coefficient of the same feature have opposite signs. How can this be? For example, when a feature A is positively correlated with the outcome Y but also positively correlated with a different feature B that has a negative effect on Y, then the indirect correlation (A->B->Y) can overwhelm the direct correlation (A->Y). In such a case, the regression coefficient of feature A could be positive, while the correlation coefficient is negative. This is sometimes called a masking relationship. Let’s see if the multivariate regression can reveal such a phenomenon.
# Import the linear model function from sklearn
from sklearn import linear_model
# Create the features and target DataFrames
features = car_acc[['perc_fatl_speed', 'perc_fatl_alcohol', 'perc_fatl_1st_time']]
target = car_acc['drvr_fatl_col_bmiles']
# Create a linear regression object
reg = linear_model.LinearRegression()
# Fit a multivariate linear regression model
# ... YOUR CODE FOR TASK 5 ...
reg.fit(features, target)
# Retrieve the regression coefficients
fit_coef = reg.coef_
fit_coef
array([-0.04180041, 0.19086404, 0.02473301])
6. Perform PCA on standardized data
We have learned that alcohol consumption is weakly associated with the number of fatal accidents across states. This could lead us to conclude that alcohol consumption should be a focus for further investigations and maybe strategies should divide states into high versus low alcohol consumption in accidents. But there are also associations between alcohol consumptions and the other two features, so it might be worth trying to split the states in a way that accounts for all three features.
One way of clustering the data is to use PCA to visualize data in reduced dimensional space where we can try to pick up patterns by eye. PCA uses the absolute variance to calculate the overall variance explained for each principal component, so it is important that the features are on a similar scale (unless we would have a particular reason that one feature should be weighted more).
We'll use the appropriate scaling function to standardize the features to be centered with mean 0 and scaled with standard deviation 1.
# Standardize and center the feature columns
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
features_scaled = scaler.fit_transform(features)
# Import the PCA class function from sklearn
# ... YOUR CODE FOR TASK 6 ...
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(features_scaled)
# Fit the standardized data to the pca
# ... YOUR CODE FOR TASK 6 ...
# Plot the proportion of variance explained on the y-axis of the bar plot
import matplotlib.pyplot as plt
plt.bar(range(1, pca.n_components_ + 1), pca.explained_variance_ratio_)
plt.xlabel('Principal component #')
plt.ylabel('Proportion of variance explained')
plt.xticks([1, 2, 3])
# Compute the cumulative proportion of variance explained by the first two principal components
two_first_comp_var_exp = pca.explained_variance_.cumsum()[1]
print("The cumulative variance of the first two principal components is {}".format(round(two_first_comp_var_exp, 5)))
The cumulative variance of the first two principal components is 2.43178
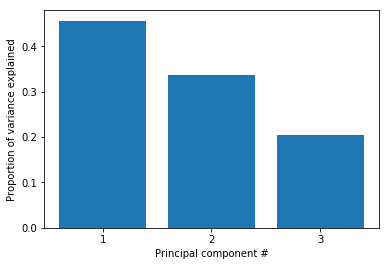
7. Visualize the first two principal components
The first two principal components enable visualization of the data in two dimensions while capturing a high proportion of the variation (79%) from all three features: speeding, alcohol influence, and first-time accidents. This enables us to use our eyes to try to discern patterns in the data with the goal to find groups of similar states. Although clustering algorithms are becoming increasingly efficient, human pattern recognition is an easily accessible and very efficient method of assessing patterns in data.
We will create a scatter plot of the first principle components and explore how the states cluster together in this visualization.
# Transform the scaled features using two principal components
pca = PCA(n_components=2)
p_comps = pca.fit_transform(features_scaled)
# Extract the first and second component to use for the scatter plot
p_comp1 = p_comps[:, 0]
p_comp2 = p_comps[:, 1]
# Plot the first two principal components in a scatter plot
# ... YOUR CODE FOR TASK 7 ...
plt.scatter(p_comp1, p_comp2)
<matplotlib.collections.PathCollection at 0x7fda992056a0>
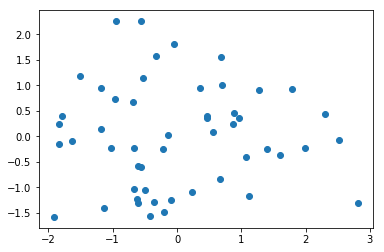
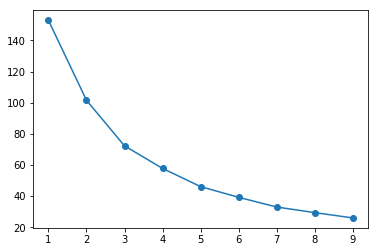
8. Find clusters of similar states in the data
It was not entirely clear from the PCA scatter plot how many groups in which the states cluster. To assist with identifying a reasonable number of clusters, we can use KMeans clustering by creating a scree plot and finding the "elbow", which is an indication of when the addition of more clusters does not add much explanatory power.
# Import KMeans from sklearn
# ... YOUR CODE FOR TASK 8 ...
from sklearn.cluster import KMeans
# A loop will be used to plot the explanatory power for up to 10 KMeans clusters
ks = range(1, 10)
inertias = []
for k in ks:
# Initialize the KMeans object using the current number of clusters (k)
km = KMeans(n_clusters=k, random_state=8)
# Fit the scaled features to the KMeans object
km.fit(features_scaled)
# Append the inertia for `km` to the list of inertias
inertias.append(km.inertia_)
# Plot the results in a line plot
plt.plot(ks, inertias, marker='o')
[<matplotlib.lines.Line2D at 0x7fda61dc3390>]
9. KMeans to visualize clusters in the PCA scatter plot
Since there wasn't a clear elbow in the scree plot, assigning the states to either two or three clusters is a reasonable choice, and we will resume our analysis using three clusters. Let's see how the PCA scatter plot looks if we color the states according to the cluster to which they are assigned.
# Create a KMeans object with 3 clusters, use random_state=8
km = KMeans(n_clusters=3, random_state=8)
# Fit the data to the `km` object
# ... YOUR CODE FOR TASK 9 ...
km.fit(features_scaled)
# Create a scatter plot of the first two principal components
# and color it according to the KMeans cluster assignment
# ... YOUR CODE FOR TASK 9 ...
plt.scatter(p_comps[:, 0], p_comps[:, 1], c=km.labels_)
<matplotlib.collections.PathCollection at 0x7fda65b0c518>
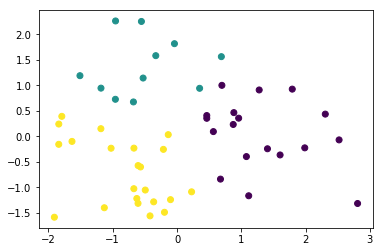
10. Visualize the feature differences between the clusters
Thus far, we have used both our visual interpretation of the data and the KMeans clustering algorithm to reveal patterns in the data, but what do these patterns mean?
Remember that the information we have used to cluster the states into three distinct groups are the percentage of drivers speeding, under alcohol influence and that has not previously been involved in an accident. We used these clusters to visualize how the states group together when considering the first two principal components. This is good for us to understand structure in the data, but not always easy to understand, especially not if the findings are to be communicated to a non-specialist audience.
A reasonable next step in our analysis is to explore how the three clusters are different in terms of the three features that we used for clustering. Instead of using the scaled features, we return to using the unscaled features to help us interpret the differences.
# Create a new column with the labels from the KMeans clustering
car_acc['cluster'] = km.labels_
# Reshape the DataFrame to the long format
melt_car = pd.melt(car_acc, id_vars='cluster', var_name='measurement', value_name='percent',
value_vars=['perc_fatl_speed', 'perc_fatl_alcohol', 'perc_fatl_1st_time'])
# Create a violin plot splitting and coloring the results according to the km-clusters
sns.violinplot(y='measurement', x='percent', data=melt_car, hue='cluster')
<matplotlib.axes._subplots.AxesSubplot at 0x7fda65b24a90>
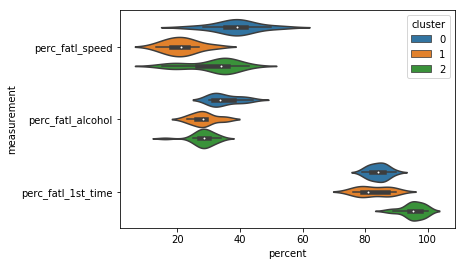
11. Compute the number of accidents within each cluster
Now it is clear that different groups of states may require different interventions. Since resources and time are limited, it is useful to start off with an intervention in one of the three groups first. Which group would this be? To determine this, we will include data on how many miles are driven in each state, because this will help us to compute the total number of fatal accidents in each state. Data on miles driven is available in another tab-delimited text file. We will assign this new information to a column in the DataFrame and create a violin plot for how many total fatal traffic accidents there are within each state cluster.
# Read in the new dataset
miles_driven = pd.read_csv('datasets/miles-driven.csv', sep='|')
# Merge the `car_acc` DataFrame with the `miles_driven` DataFrame
car_acc_miles = carr_acc.merge(...)
# Create a new column for the number of drivers involved in fatal accidents
car_acc_miles['num_drvr_fatl_col'] = ...
# Create a barplot of the total number of accidents per cluster
sns.barplot(x=..., y=..., data=..., estimator=..., ci=None)
# Calculate the number of states in each cluster and their 'num_drvr_fatl_col' mean and sum.
count_mean_sum = ...
count_mean_sum
12. Make a decision when there is no clear right choice
As we can see, there is no obvious correct choice regarding which cluster is the most important to focus on. Yet, we can still argue for a certain cluster and motivate this using our findings above. Which cluster do you think should be a focus for policy intervention and further investigation?
# Which cluster would you choose?
cluster_num = ...
Sunny Arokia Swamy Bellary
Research Engineer - Robotics
EPRI Engineer | AI Enthusiast | Computer Vision Researcher | Robotics Tech Savvy | Food Lover | Wanderlust | Team Leader @Belaku | Musician |