Name Game - Gender Prediction using Sound
The same name can be spelled out in a many ways (for example, Marc and Mark, or Elizabeth and Elisabeth). Sound can, therefore, be a better way to match names than spelling. In this project, you will use the Python package Fuzzy to find out the genders of authors that have appeared in the New York Times Best Seller list for Children’s Picture books.
First, using fuzzy (sound) name matching, you will search for author names in a dataset provided by the US Social Security Administration that contains names and genders of all individuals who have applied for Social Security Cards. Next, we’ll aggregate the author dataset by including gender. Finally, you will use the new dataset to plot the gender distribution of children’s picture books authors over time.
To complete this project, you should be familiar with pandas DataFrames, NumPy for basic statistics, and Matplotlib for plotting.
1. Sound it out!
Grey and Gray. Colour and Color. Words like these have been the cause of many heated arguments between Brits and Americans. Accents (and jokes) aside, there are many words that are pronounced the same way but have different spellings. While it is easy for us to realize their equivalence, basic programming commands will fail to equate such two strings.
More extreme than word spellings are names because people have more flexibility in choosing to spell a name in a certain way. To some extent, tradition sometimes governs the way a name is spelled, which limits the number of variations of any given English name. But if we consider global names and their associated English spellings, you can only imagine how many ways they can be spelled out.
One way to tackle this challenge is to write a program that checks if two strings sound the same, instead of checking for equivalence in spellings. We'll do that here using fuzzy name matching.
# Importing the fuzzy package
import fuzzy
# Exploring the output of fuzzy.nysiis
fuzzy.nysiis('Sunny')
# Testing equivalence of similar sounding words
fuzzy.nysiis('SANNY')
'SANY'
2. Authoring the authors
The New York Times puts out a weekly list of best-selling books from different genres, and which has been published since the 1930’s. We’ll focus on Children’s Picture Books, and analyze the gender distribution of authors to see if there have been changes over time. We'll begin by reading in the data on the best selling authors from 2008 to 2017.
# Importing the pandas module
import pandas as pd
# Reading in datasets/nytkids_yearly.csv, which is semicolon delimited.
author_df = pd.read_csv('datasets/nytkids_yearly.csv', delimiter=';')
# Looping through author_df['Author'] to extract the authors first names
first_name = []
for name in author_df['Author']:
first_name.append(name.split()[0])
# Adding first_name as a column to author_df
author_df['first_name'] = first_name
# Checking out the first few rows of author_df
author_df.head()
| Year | Book Title | Author | Besteller this year | first_name | |
|---|---|---|---|---|---|
| 0 | 2017 | DRAGONS LOVE TACOS | Adam Rubin | 49 | Adam |
| 1 | 2017 | THE WONDERFUL THINGS YOU WILL BE | Emily Winfield Martin | 48 | Emily |
| 2 | 2017 | THE DAY THE CRAYONS QUIT | Drew Daywalt | 44 | Drew |
| 3 | 2017 | ROSIE REVERE, ENGINEER | Andrea Beaty | 38 | Andrea |
| 4 | 2017 | ADA TWIST, SCIENTIST | Andrea Beaty | 28 | Andrea |
3. It’s time to bring on the phonics… again!
When we were young children, we were taught to read using phonics; sounding out the letters that compose words. So let's relive history and do that again, but using python this time. We will now create a new column or list that contains the phonetic equivalent of every first name that we just extracted.
To make sure we're on the right track, let's compare the number of unique values in the first_name column and the number of unique values in the nysiis coded column. As a rule of thumb, the number of unique nysiis first names should be less than or equal to the number of actual first names.
# Importing numpy
import numpy as np
# Looping through author's first names to create the nysiis (fuzzy) equivalent
nysiis_name = []
for name in author_df['first_name']:
nysiis_name.append(fuzzy.nysiis(name))
# Adding nysiis_name as a column to author_df
author_df['nysiis_name'] = nysiis_name
# Printing out the difference between unique firstnames and unique nysiis_names:
np.unique(author_df['nysiis_name'])
np.unique(author_df['first_name'])
array(['Aaron', 'Adam', 'Ahmet', 'Ainsley', 'Al', 'Ame', 'Amy', 'Andrea',
'Anna', 'Antoine', 'Barack', 'Barb', 'Barbara', 'Beatrix',
'Benjamin', 'Berkeley', 'Beryl', 'Beth', 'Bill', 'Bonny', 'Brad',
'Brandon', 'Brendan', 'Brian', 'Buzz', 'Callista', 'Carl',
'Carmen', 'Caroline', 'Carson', 'Cathy', 'Charlie', 'Chelsea',
'Chris', 'Christopher', 'Clement', 'Cokie', 'Cynthia', 'Dan',
'Danica', 'David', 'Debbie', 'Deborah', 'Doreen', 'Drew', 'Ed',
'Elise', 'Eliza', 'Elle', 'Emily', 'Emma', 'Eric', 'Ferdinand',
'Gary', 'Glenn', 'Graeme', 'Greg', 'Herman', 'Herve', 'Hillary',
'Holly', 'Ian', 'Jacky', 'James', 'Jamie', 'Jan', 'Jane', 'Javaka',
'Jean', 'Jeff', 'Jennifer', 'Jenny', 'Jerry', 'Jimmy', 'Jo',
'Joan', 'John', 'Jon', 'Jonah', 'Joyce', 'Judy', 'Julia', 'Julian',
'Julianne', 'Julie', 'Kabir', 'Kareem', 'Karma', 'Kate',
'Katherine', 'Kathie', 'Keith', 'Kelly', 'Kevin', 'Kimberly',
'Kobi', 'Kristi', 'Laban', 'Lane', 'Laura', 'Laurie', 'Lemony',
'Lindsay', 'Liz', 'Lora', 'Loren', 'Lori', 'Louise', 'Lucy',
'Lynne', 'Mac', 'Malala', 'Marc', 'Margaret', 'Marion', 'Mark',
'Mary', 'Matt', 'Matthew', 'Maurice', 'Maya', 'Mem', 'Michael',
'Mike', 'Mo', 'Nancy', 'Neil', 'Nick', 'Nikki', 'Norton', 'Oliver',
'Olivier', 'Patricia', 'Patrick', 'Peter', 'Peyton', 'Pharrell',
'Philip', 'Pope', 'Queen', 'R.', 'Ree', 'Rob', 'Robert', 'Rufus',
'Ryan', 'Sandra', 'Sarah', 'Savannah', 'Sean', 'Shel', 'Sherman',
'Sherri', 'Simon', 'Sophia', 'Steve', 'Susan', 'Tad', 'Tedd',
'Theodor', 'Todd', 'Tomie', 'Toni', 'Tony', 'Vicki', 'Victoria',
'Walter', 'William', 'Ylvis', 'illustrated'], dtype=object)
4. The inbetweeners
We'll use babynames_nysiis.csv, a dataset that is derived from the Social Security Administration’s baby name data, to identify author genders. The dataset contains unique NYSIIS versions of baby names, and also includes the percentage of times the name appeared as a female name (perc_female) and the percentage of times it appeared as a male name (perc_male).
We'll use this data to create a list of gender. Let's make the following simplifying assumption: For each name, if perc_female is greater than perc_male then assume the name is female, if perc_female is less than perc_male then assume it is a male name, and if the percentages are equal then it's a "neutral" name.
# Reading in datasets/babynames_nysiis.csv, which is semicolon delimited.
babies_df = pd.read_csv('datasets/babynames_nysiis.csv', delimiter=';')
# Looping through babies_df to and filling up gender
gender = []
for idx in range(len(babies_df['babynysiis'])):
if babies_df.loc[idx, 'perc_female'] > babies_df.loc[idx, 'perc_male']:
gender.append('F')
elif babies_df.loc[idx, 'perc_female'] < babies_df.loc[idx, 'perc_male']:
gender.append('M')
else:
gender.append('N')
# Adding a gender column to babies_df
babies_df['gender'] = gender
# Printing out the first few rows of babies_df
print(babies_df.head())
babynysiis perc_female perc_male gender
0 NaN 62.50 37.50 F
1 RAX 63.64 36.36 F
2 ESAR 44.44 55.56 M
3 DJANG 0.00 100.00 M
4 PARCAL 25.00 75.00 M
5. Playing matchmaker
Now that we have identified the likely genders of different names, let's find author genders by searching for each author's name in the babies_df DataFrame, and extracting the associated gender.
# This function returns the location of an element in a_list.
# Where an item does not exist, it returns -1.
def locate_in_list(a_list, element):
loc_of_name = a_list.index(element) if element in a_list else -1
return(loc_of_name)
# Looping through author_df['nysiis_name'] and appending the gender of each
# author to author_gender.
author_gender = []
for name in author_df['nysiis_name']:
nloc = locate_in_list(list(babies_df['babynysiis']), name)
if nloc == -1:
author_gender.append('Unknown')
else:
author_gender.append(babies_df['gender'][nloc])
# Adding author_gender to the author_df
author_df['author_gender'] = author_gender
# Counting the author's genders
author_df['author_gender'].value_counts()
F 395
M 191
Unknown 9
N 8
Name: author_gender, dtype: int64
6. Tally up
From the results above see that there are more female authors on the New York Times best seller's list than male authors. Our dataset spans 2008 to 2017. Let's find out if there have been changes over time.
# Creating a list of unique years, sorted in ascending order.
years = list(np.unique(author_df.Year))
# Intializing lists
males_by_yr = []
females_by_yr = []
unknown_by_yr = []
# Looping through years to find the number of male, female and unknown authors per year
for yr in years:
males_by_yr.append(
len(author_df[(author_df["author_gender"] == 'M') & (author_df["Year"] == yr)]))
females_by_yr.append(
len(author_df[(author_df["author_gender"] == 'F') & (author_df["Year"] == yr)]))
unknown_by_yr.append(len(
author_df[(author_df["author_gender"] == 'Unknown') & (author_df["Year"] == yr)]))
# Printing out yearly values to examine changes over time
data = np.array([males_by_yr, females_by_yr, unknown_by_yr])
headers = ['males', 'females', 'unknowns']
pd.DataFrame(data, headers, years)
| 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | |
|---|---|---|---|---|---|---|---|---|---|---|
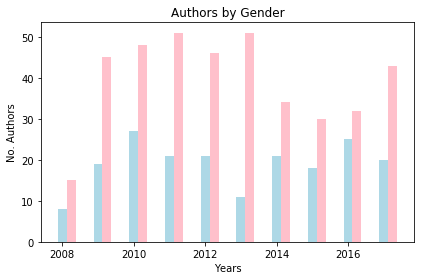
| males | 8 | 19 | 27 | 21 | 21 | 11 | 21 | 18 | 25 | 20 |
| females | 15 | 45 | 48 | 51 | 46 | 51 | 34 | 30 | 32 | 43 |
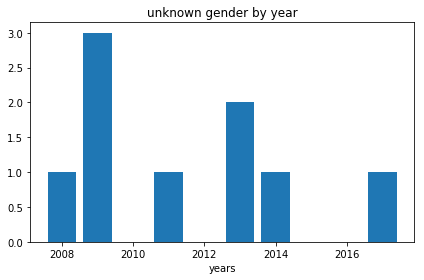
| unknowns | 1 | 3 | 0 | 1 | 0 | 2 | 1 | 0 | 0 | 1 |
7. Foreign-born authors?
Our gender data comes from social security applications of individuals born in the US. Hence, one possible explanation for why there are "unknown" genders associated with some author names is because these authors were foreign-born. While making this assumption, we should note that these are only a subset of foreign-born authors as others will have names that have a match in baby_df (and in the social security dataset).
Using a bar chart, let's explore the trend of foreign-born authors with no name matches in the social security dataset.
# Importing matplotlib
import matplotlib.pyplot as plt
# This makes plots appear in the notebook
%matplotlib inline
# Plotting the bar chart
plt.bar(years, unknown_by_yr)
# [OPTIONAL] - Setting a title, and axes labels
plt.title('unknown gender by year')
plt.xlabel('years')
Text(0.5,0,'years')
8. Raising the bar
What’s more exciting than a bar chart is a grouped bar chart. This type of chart is good for displaying changes over time while also comparing two or more groups. Let’s use a grouped bar chart to look at the distribution of male and female authors over time.
# Creating a new list, where 0.25 is added to each year
years_shifted = [year + 0.25 for year in years]
# Plotting males_by_yr
plt.bar(years, males_by_yr, width=0.25, color='lightblue')
# Plotting females_by_yr by years_shifted
plt.bar(years_shifted, females_by_yr, width=0.25, color='pink')
# [OPTIONAL] - Adding relevant Axes labels and Chart Title
plt.xlabel('Years')
plt.ylabel('No. Authors')
plt.title('Authors by Gender')
Text(0.5,1,'Authors by Gender')
Credits
This is a Datacamp project and I Thank Tufool Alnuaimi a Academic entrepreneur at Datacamp for designing this project for datacamp.
Sunny Arokia Swamy Bellary
Research Engineer - Robotics
EPRI Engineer | AI Enthusiast | Computer Vision Researcher | Robotics Tech Savvy | Food Lover | Wanderlust | Team Leader @Belaku | Musician |